#선형회귀 #경사하강법 #다항회귀 #데이콘
#LinearRegression #GradientDescent #Polynomial
머신러닝 모델 중 가장 기본이 되는 선형회귀(Linear Regression).
그에서 비롯된 경사하강법(Gradient Descent), 다항회귀(Polynomial Regression), 그리고 (다음 포스팅에서) 릿지, 라쏘, 엘라스틱넷에 대해서 정리해보려 한다.
(python의 scikit learn 라이브러리 활용 방법과 파라미터에 대한 간단한 이해 위주, 수식은 간단한 이해만)
선형회귀는 이해가 쉽고 직관적이라 특성과 모델 사이 인과관계 파악이 쉽다.
그 활용인 라쏘회귀 모델은 특성 선택(feature selection)을 할 수 있다는 특징이 있다.
비교적 간단한 모델임에도 활용도가 높고, 특히 데이터 기반 의사결정 시 최종 판단은 사람이 한다는 점에서 인과 증명이 명확한 선형 모델을 선호할 수도 있을 것이다. (현업에서도 많이 쓰인다는 건 주워들은 말..)
참고한 데이터&코드
(데이콘 MIND 님의 코드 공유 전처리 과정 활용)
준비
sklearn 라이브러리의 linear_model 패키지 안에는 선형 모델 모듈들이 들어있다.
(다항 회귀를 사용하려면 preprocessing 패키지 안에 있는 PolynomialFeatures 모듈을 사용해 다항 특성을 추가해야 한다.)
아래와 같은 코드를 실행하여 패키지들을 추가하였다.
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import SGDRegressor
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.preprocessing import StandardScaler
위 링크의 코드에 대해 아래 코드를 실행하여 훈련, 테스트 세트를 만들어 아래에 설명할 모델들에 사용했다.
# train_test_split으로 훈련, 테스트 세트 셔플
from sklearn.model_selection import train_test_split
y_target = tmp_train['등록차량수']
X_data = tmp_train.drop(['단지코드', '등록차량수'], axis=1, inplace=False)
X_train, X_test, y_train, y_test = train_test_split(X_data, y_target, shuffle=False, random_state=42, test_size=0.1)
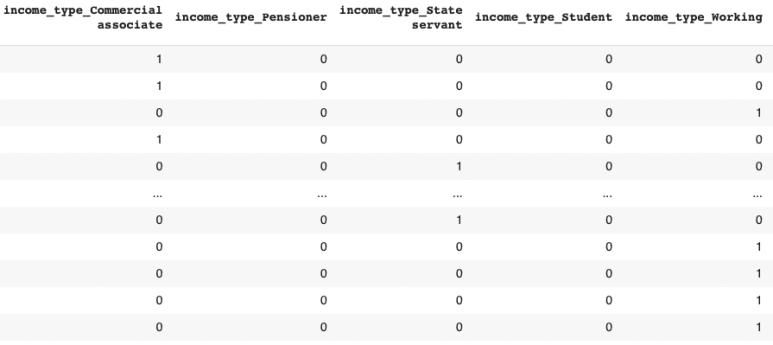
전처리된 데이터 셋(tmp_train)은 다음과 같다.

선형회귀(Linear Regression)
선형회귀는 아래와 같은 식으로 표현할 수 있다.
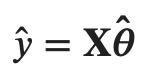
y는 예측값, X는 특성벡터, theta는 가중치벡터인데,
X와 theta가 벡터가 아닌 1차원의 값이라고 한다면 가중치는 x의 계수인 일차함수 꼴이 될 것이다.
즉, 우리가 예측하려는 y가 X와 선형적인 관계라고 가정하고 가장 이상적인 theta를 구하는 알고리즘이다.
이상적인 theta는 비용 함수(loss function)을 설정하고 그것을 최소화하는 것을 의미하는데,
선형회귀의 비용 함수는 MSE(Mean Squared Error)이다.
(실제 타겟의 값(y)와 예측한 값(y, 정확히는 y hat)의 차이의 제곱의 평균 (편차의 제곱의 평균)을 의미한다.)
특성벡터 X와 타깃의 값들을 담고 있는 벡터 y를 가지고 MSE를 최소화하는 가중치벡터 theta를 바로 구할 수가 있는데,

위의 식이 성립함이 알려져 있다. (정규방정식)
정규방정식 계산을 위한 X^T * X 의 역행렬 계산복잡도는 일반적으로 아래와 같다. (n은 특성 수)
따라서 특성 수에 계산 속도가 굉장히 민감하다.
하지만 특성의 스케일과는 무관하다. 스케일이 크다면 가중치가 작도록, 스케일이 작다면 가중치가 크도록 정규방정식이 계산될 것이기 때문이다.
아래 코드로 LinearRegression 모델을 학습해 테스트 세트에 대한 점수를 구해보았다.
# 선형회귀 모델 훈련 및 지표(MAE) 산출
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
print(f'MAE : {mean_absolu코드te_error(model.predict(X_test), y_test)}')위에서 알 수 있듯이 LinearRegression 모듈은 파라미터가 없다.
정규방정식(정확히는 특잇값 분해라는 방법을 통한 유사역행렬 계산)을 통해 최적의(MSE를 최소화하는) 가중치 벡터 theta를 계산하기 때문에 별도의 파라미터가 존재하지 않는다.
실행 결과는 아래와 같다. (아래 모델과의 비교를 위한 결과 출력)
MAE : 106.34272775431835
경사하강법(Gradient Descent)
경사하강법은 가중치벡터 theta를 비용 함수의 현재 그레디언트가 감소하는 방향으로 움직이며 최적의 theta를 찾는 방법이다.
쉽게 말하자면, theta를 증가시킬 때 비용이 감소한다면 theta를 증가시키고, 반대라면 감소시키는 방법으로, 비용 함수가 최솟값에 도달할 때까지 theta를 수정한다.
실제 MSE를 최소화하는 정규방정식이란 식이 존재함에도 경사하강법을 사용하는 데에는 이유가 있다.
첫째는 계산 속도가 빠르다.
둘째는 외부 메모리 학습을 지원한다(확률적 경사하강법, 미니배치 경사하강법)
가장 중요한 점은, 경사하강법이 특성의 스케일에 민감하다는 점이다. 한 점에서 많은 그레디언트를 계산한다면, 특성의 스케일이 큰 값의 그레디언트에 민감하여 작은 값의 학습은 상대적으로 더딜 것이기 때문이다. 결국에는 최솟값에 도달하겠지만 시간이 매우 오래 걸린다.
따라서 아래 코드를 통해 스케일링을 진행한다.
scaler = StandardScaler()
# 훈련 데이터 만들기
tmp_train = df_train[['등록차량수', '단지코드', 'n지역', 'n공급유형', '공가수', '지하철', '버스', '단지내주차면수', '총임대세대수', '평균전용면적', '총전용면적', 'log_평균임대보증금', 'log_평균임대료']]
y_target = tmp_train['등록차량수']
X_data = tmp_train.drop(['단지코드', '등록차량수'], axis=1, inplace=False)
# 전체 scaled
X_data_scaled = scaler.fit_transform(X_data)
# train_test_split으로 훈련, 테스트 세트 셔플
X_train, X_test, y_train, y_test = train_test_split(X_data_scaled, y_target, shuffle=False, random_state=42, test_size=0.1)
자세한 설명은 생략하고, 경사하강법(SGDRegressor) 모델을 사용해 보자.
아래에서 사용한 확률적 경사하강법은 랜덤한 1개의 샘플을 추출해 그레디언트를 계산하는 방법이다.
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1)
sgd_reg.fit(X_train, y_train.ravel())
print(f'MAE : {mean_absolute_error(sgd_reg.predict(X_test), y_test)}')파라미터의 역할은 아래와 같다.
max_iter : 최대 학습 횟수. 해당 파라미터 초과 횟수로는 학습하지 않는다.
tol : 허용 오차. 해당 파라미터 값보다 적은 학습 오차를 보이는 경우 학습을 멈춘다. 즉, 학습 후에도 비용 함수가 해당 파라미터 값보다 적다면 최솟값과 아주 근접하다고 판단하고 학습을 멈춘다.
penalty : 규제 종류로, 해당 파라미터를 l1, l2 등으로 설정하면 경사하강법으로 근사한 릿지, 라쏘 회귀 등을 구현할 수 있다.
eta0 : 학습률을 결정하는 파라미터.
실행 결과는 다음과 같다.
MAE : 112.38517315046478
LinearRegressor가 MSE를 최소화하는 수학적 모델이긴 하지만, 경사하강법은 선형 회귀를 근사한 것이므로 MAE 점수도 약간 낮은 것을 확인할 수 있다.
다항 회귀(Polynomial Regression)
선형회귀 모델은 특성과 타겟의 선형관계를 가정한다. 따라서 특성과 타겟이 선형이 아닌 제곱관계, 로그관계 등이라면 선형회귀 모델은 과소적합될 것이다.
PolynomialFeatures 모듈을 사용하면, 존재하는 특성들의 다항 특성들을 생성해 준다.
예를 들어 [a, b, c]의 특성이 존재한다면
aa, ab, ac, bb, bc, cc 라는 특성을 기존 특성에 추가해 준다. (총 3개에서 9개의 특성을 가지게 됨)
# 다항 특성 추가
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X_data_scaled)(위 코드를 실행한 후, 포스팅 상단에 있는 훈련, 테스트 셔플 코드를 실행해야 한다.)
파라미터의 역할은 아래와 같다.
degree : 차수 (예를 들어 3이라면 각 특성을 2번, 3번 곱한 특성들을 모두 더해준다.)
include_bias : 편향 포함 여부(편향이란 일차함수의 상수 같은 개념으로, 특성에 영향받지 않고 더해주는 파라미터이다.)
다항 회귀는 다항 특성을 추가한 후 LinearRegression 모델을 사용하기 때문에, 마찬가지로 특성의 스케일과는 무관하다.
다항 특성을 추가한 데이터로 LinearRegression 모델을 학습해 보자.
model = LinearRegression()
model.fit(X_train, y_train)
print(f'MAE : {mean_absolute_error(model.predict(X_test), y_test)}')MAE : 150.90253260297598
결과는 다항 특성을 추가하기 전보다 나빠졌다.
해당 데이터가 특성과 타겟 간 다항관계가 존재하지 않아 보여 그런 것 같다.
(특성 선택 알고리즘을 통해 확인할 수 있을 것이다.)
'Data Science' 카테고리의 다른 글
| 더미형 변수 생성 / 숫자형(Numeric), 범주형(Category) 컬럼 분류 / 라벨 인코딩(Label Encoding) (0) | 2022.03.25 |
|---|---|
| 데이콘 주차수요 예측 데이터 분석 / 선형회귀(Linear Regression) 모델 적용 (0) | 2022.03.25 |