Oct 28, 2022 8:15:45 PM org.junit.platform.launcher.core.EngineDiscoveryOrchestrator lambda$logTestDescriptorExclusionReasons$7
INFO: 0 containers and 10 tests were Method or class mismatch
에러 상황
- 테스트 코드 중 특정 클래스만 실행할 때 발생했다.
에러 이유
작성된 테스트 코드 중 특정 클래스만 실행했다는 경고문이다.
실제로 실행시킨 테스트 코드는 잘 실행되었으며, 전체 테스트 코드 실행 시 해당 경고문이 발생하지 않았다.
테스트에는 아무 문제가 없었다.
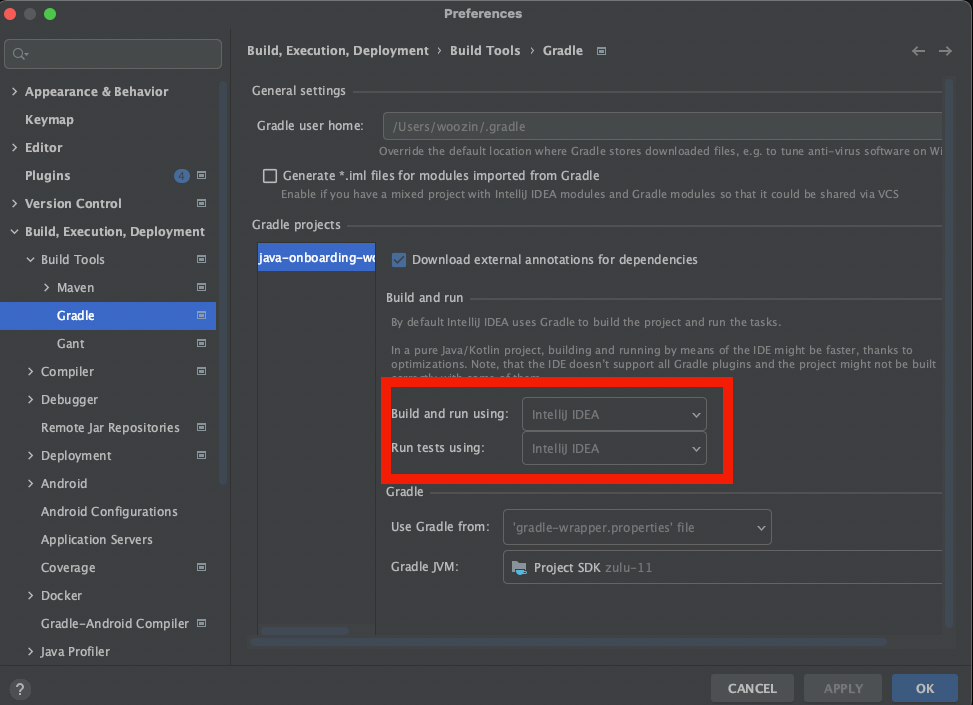
또한, 빌드할 때 JUnit으로 테스트가 진행 되어야 하는데 Gradle로 되어서 발생하는 것이라고 한다.
Project language level은 IntelliJ의 editor(편집기)와 java compiler가 사용할 language level을 설정한다.예를 들어, JDK 1.7을 사용하고 있지만 java 코드가 JDK 1.6과 호환되도록 하려면language level을실제 JDK 지원(JDK 1.7의 경우 7.0)보다 낮은 6.0으로 설정하면 된다.
Java 컴파일러 명령인javac의 옵션을 보면 -source 및 -target 옵션을 통해 Java의 대체 버전을 기준으로 컴파일할 수 있음을 알 수 있다. 이를 통해 Project language level은 IntelliJ에게 특정 Java 언어 버전에서 제공된 Java SDK를 사용하도록 지시한다. 그래서 Java 7이 설치되어 있어도 language level을 6.0으로 설정할 수 있고, IntelliJ는 Java 7 대신 Java 6을 기준으로 코드를 확인하고, suggestion을 제공하며, 컴파일한다.
[Nest] 64896 - 2022. 10. 13. 오후 8:00:56 ERROR [ExceptionHandler] Nest can't resolve dependencies of the ScriptService (FirstRepository, SecondRepository, ThirdRepository, ?). Please make sure that the argument SentenceRepository at index [3] is available in the ScriptModule context.
Potential solutions: - If SentenceRepository is a provider, is it part of the current ScriptModule? - If SentenceRepository is exported from a separate @Module, is that module imported within ScriptModule? @Module({ imports: [ /* the Module containing SentenceRepository */ ] })
에러 내용 해석
Nest가 ScriptService에 ?에 해당하는 것의 의존성 주입을 할 수 없다는 뜻이다.
나는 Potential solutions 중 첫번째에 해당하는 간단한 오류였다.
ScriptModule에 SentenceRepository를 import하지 않고, ScriptService의 생성자에 추가했기 때문에 발생한 오류다.
첫째 줄에 수의 개수 N(1 ≤ N ≤ 10,000,000)이 주어진다. 둘째 줄부터 N개의 줄에는 수가 주어진다. 이 수는 10,000보다 작거나 같은 자연수이다.
출력
첫째 줄부터 N개의 줄에 오름차순으로 정렬한 결과를 한 줄에 하나씩 출력한다.
예제 입력 1
10
5
2
3
1
4
2
3
5
1
7
예제 출력 1
1
1
2
2
3
3
4
5
5
7
틀린 풀이
import sys
n = int(sys.stdin.readline().rstrip())
array = []
for _ in range(n):
array.append(int(sys.stdin.readline().rstrip()))
for _ in range(n):
for i in range(n - 1):
if array[i] > array[i + 1]:
array[i], array[i + 1] = array[i + 1], array[i]
for number in array:
print(number)
이유
메모리 초과
메모리를 줄이려고 버블 정렬을 써가며 별짓을 다 했으나, 10,000,000 크기의 리스트를 줄일 수 없어 시실패하였다.
맞은 풀이1
import sys
n = int(sys.stdin.readline().rstrip())
count_array = [0] * 10001
for i in range(n):
count_array[int(sys.stdin.readline().rstrip())] += 1
for i in range(10001):
if count_array[i] != 0:
for j in range(count_array[i]):
print(i)
접근 방식
계수 정렬을 사용!
입력값의 범위가 10,000 이하이므로, 리스트의 크기가 10,000,000에서 10,000으로 줄어든다.
수를 처리하는 것은 통계학에서 상당히 중요한 일이다. 통계학에서 N개의 수를 대표하는 기본 통계값에는 다음과 같은 것들이 있다. 단, N은 홀수라고 가정하자.
산술평균 : N개의 수들의 합을 N으로 나눈 값
중앙값 : N개의 수들을 증가하는 순서로 나열했을 경우 그 중앙에 위치하는 값
최빈값 : N개의 수들 중 가장 많이 나타나는 값
범위 : N개의 수들 중 최댓값과 최솟값의 차이
N개의 수가 주어졌을 때, 네 가지 기본 통계값을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 수의 개수 N(1 ≤ N ≤ 500,000)이 주어진다. 단, N은 홀수이다. 그 다음 N개의 줄에는 정수들이 주어진다. 입력되는 정수의 절댓값은 4,000을 넘지 않는다.
출력
첫째 줄에는 산술평균을 출력한다. 소수점 이하 첫째 자리에서 반올림한 값을 출력한다.
둘째 줄에는 중앙값을 출력한다.
셋째 줄에는 최빈값을 출력한다. 여러 개 있을 때에는 최빈값 중 두 번째로 작은 값을 출력한다.
넷째 줄에는 범위를 출력한다.
예제 입력 1
5
1
3
8
-2
2
예제 출력 1
2
2
1
10
예제 입력 2
1
4000
예제 출력 2
4000
4000
4000
0
예제 입력 3
5
-1
-2
-3
-1
-2
예제 출력 3
-2
-2
-1
2
예제 입력 4
3
0
0
-1
예제 출력 4
0
0
0
1
(0 + 0 + (-1)) / 3 = -0.333333... 이고 이를 첫째 자리에서 반올림하면 0이다. -0으로 출력하면 안된다.
내 풀이
import sys
from collections import Counter
n = int(sys.stdin.readline().rstrip())
array = []
for i in range(n):
array.append(int(sys.stdin.readline().rstrip()))
array.sort()
s = sum(array)
max_number = max(array)
min_number = min(array)
length_array = len(array)
# 최빈값 구하는 로직
counter = Counter(array)
mode = counter.most_common() # 숫자:빈도 를 나타내는 튜플을 빈도 순으로 나열
mode = [i for i in mode if i[1] == mode[0][1]] # 빈도수가 최빈값과 같은 튜플들만 남긴다
mode_result = []
# 빈도가 아닌 숫자만 남긴다
for i in mode:
mode_result.append(i[0])
mode_result.sort() # 정렬
# 최빈값이 2개 이상이면 2번째로 작은 수를, 아니면 최빈값을 저장한다.
if len(mode_result) >= 2:
mode_number = mode_result[1]
else:
mode_number = mode_result[0]
# 출력
print(round(s / n))
print(array[length_array // 2])
print(mode_number)
print(max_number - min_number)
접근 방식
평균, 중앙값, 길이는 쉬우니까 pass
최빈값은 Counter 라이브러리의 most_common() 모듈을 사용하였다.
[1, 1, 1, 2, 3, 3, 3] 을 [(1, 3), (3, 3), (2, 1)] 로 바꿔주는 라이브러리
잘 조작하여 조건에 맞는 최빈값을 구하였다.
남의 풀이
import sys
from collections import Counter
n = int(sys.stdin.readline())
nums = []
for i in range(n):
nums.append(int(sys.stdin.readline()))
nums.sort()
nums_s = Counter(nums).most_common()
print(round(sum(nums) / n))
print(nums[n // 2])
if len(nums_s) > 1:
if nums_s[0][1] == nums_s[1][1]:
print(nums_s[1][0])
else:
print(nums_s[0][0])
else:
print(nums_s[0][0])
print(nums[-1] - nums[0])
접근 방식
다른 것은 볼 필요 없고, 최빈값 출력하는 로직만 보면 된다.
비슷한 로직인데, Counter 객체를 출력할 때 더 간결하게 사용하였다.
숫자 리스트 길이가 2 이상일 때, 첫번째 빈도와 두번째 빈도가 같다면 두번째 숫자를 출력
첫째 줄에 자연수 M과 N이 빈 칸을 사이에 두고 주어진다. (1 ≤ M ≤ N ≤ 1,000,000) M이상 N이하의 소수가 하나 이상 있는 입력만 주어진다.
출력
한 줄에 하나씩, 증가하는 순서대로 소수를 출력한다.
예제 입력 1
3 16
예제 출력 1
3
5
7
11
13
틀린 풀이
n, m = map(int, input().split())
start_time = time.time()
# 2 ~ m의 리스트
array = list(range(2, m + 1))
array = [2] + [i for i in array if i % 2 == 1] # 2와 3 이상의 홀수만 남긴다
index = 0
while True:
# 걸리지고 남은 맨 앞의 수부터 차례로 골라, 뒤에 있는 수를 나눠 소수를 판별한다 (에라토스테네스의 체)
array = array[0:index + 1] + [i for i in array[index + 1:] if i % array[index] != 0]
index += 1
# 끝까지 다 진행한 경우 종료
if index >= len(array):
break
# 사실 여기 올 일이 없음
if array[index] >= m:
break
# 위에서 2 ~ m 리스트로 시작했으니
# n 이상인지 판별하여 남긴다
result = [i for i in array if n <= i]
for number in result:
print(number)
end_time = time.time()
print(end_time - start_time)
이유
시간초과
에라토스테네스의 체를 사용했으나, 시간복잡도가 너무 크다.
맞은 풀이1 (시간복잡도 상으로는 틀려야 한다..)
import time
start_time = time.time()
def check_prime(number):
if number == 1:
return False
else:
for i in range(2, int(number ** 0.5 + 1)):
if number % i == 0:
return False
return True
n, m = map(int, input().split())
for i in range(n, m + 1):
if check_prime(i) == True:
print(i)
end_time = time.time()
print(end_time - start_time)
접근 방식
n이 소수인지 판별하려면, 1 ~ root(n) + 1 까지의 수로 나누어보면 된다.
→ 약수를 대칭을 이루므로, root(n) + 1 까지 나누어떨어지지 않는다면, 그 이상의 수로 나누어떨어질 일이 없기 때문.
해당 방식이 작은 수에는 더 많은 시간이 소요되지만, 큰 수에 대해서는 훨씬 적은 시간이 소요된다.
시간 복잡도 : O(N*N^0.5) → 10억 번의 연산으로 시간초과가 맞아 보인다..
맞은 풀이2
n, m = map(int, input().split())
start_time = time.time()
array = list(range(2, m + 1))
array = [2] + [i for i in array if i % 2 == 1]
index = 0
while True:
array = array[0:index + 1] + [i for i in array[index + 1:] if i % array[index] != 0]
index += 1
if index >= len(array):
break
if array[index] >= m ** 0.5 + 1:
break
result = [i for i in array if n <= i]
for number in result:
print(number)
end_time = time.time()
print(end_time - start_time)
접근 방식
에라토스테네스의 체를 이용한 풀이
에라토스테네스의 체를 사용할 때, 맞은 풀이1 처럼 m의 제곱근까지만 배수를 제거하였다. (그 이상의 배수는 존재하지 않는다! 이미 그 이하 수의 배수를 제거할 때 없어졌기 때문!)
(연산이 간결해져서 훨씬 빠르다..)
맞은 풀이3
def prime_list(n):
# 에라토스테네스의 체 초기화: n개 요소에 True 설정(소수로 간주)
sieve = [True] * n
# n의 최대 약수가 sqrt(n) 이하이므로 i=sqrt(n)까지 검사
m = int(n ** 0.5)
for i in range(2, m + 1):
if sieve[i] == True: # i가 소수인 경우
for j in range(i+i, n, i): # i이후 i의 배수들을 False 판정
sieve[j] = False
# 소수 목록 산출
return [i for i in range(2, n) if sieve[i] == True]
M, N = map(int, input().split())
N += 1
sieve = [True] * N
for i in range(2, int(N**0.5)+1):
if sieve[i]:
for j in range(2*i, N, i):
sieve[j] = False
for i in range(M, N):
if i > 1:
if sieve[i]:
print(i)
접근 방식
에라토스테네스의 체를 이용한 풀이
맞은 풀이2 를 보다 깔끔하게 정리한 풀이
실제 소수의 리스트를 남기는 것이 아니라, 1 ~ m(해당 코드에서는 n)까지의 True리스트를 만들고, 1 ~ squr(m) + 1의 배수에 해당하는 인덱스의 값을 False로 바꿨다.